Scale-Up大戰開打:各廠技術路線、中國廠商發展與產業價值鏈解析
摘要
近期NVIDIA宣布推出可供客戶在自有ASIC使用NVLink的NVLink Fusion,以及與Intel合作x86 CPU,大幅增加NVLink使用情境,又針對Inference的Prefill階段推出Rubin CPX/VR200 NVL144 CPX新機架概念,在Rubin CPX晶片間改採用PCIe 6互連。此外,UALink、SUE等開放標準也逐漸醞釀成形。中國華為近期宣布2026年第四季的Atlas 950 SuperPOD將採用UB 2.0技術,並對外開放。
在AI運算需求大幅提升下,將多個XPU高速串連成大型SuperPOD的Scale-Up技術儼然已成為算力提升關鍵,而Scale-Up市場也出現百家爭鳴局面。本篇報告主要深度解析:(1) Scale-Up技術背景;(2) NVIDIA的Scale-Up版圖與同業競爭情形;(3)中國Scale-Up發展;(4) Scale-Up Switch IC需求估計。期能提供廠商進行市場選擇、價值評估的策略建議。
一. 背景概述
二. Scale-Up技術背景
三. Scale-Up競爭格局
四. 中國Scale-Up發展
五. Switch IC需求量估算
六. 拓墣觀點
圖一 3種擴展定律(Scaling Law)
圖二 AI Model Training compute(FLOP)
圖三 2021~2025年主要CSP季資本支出
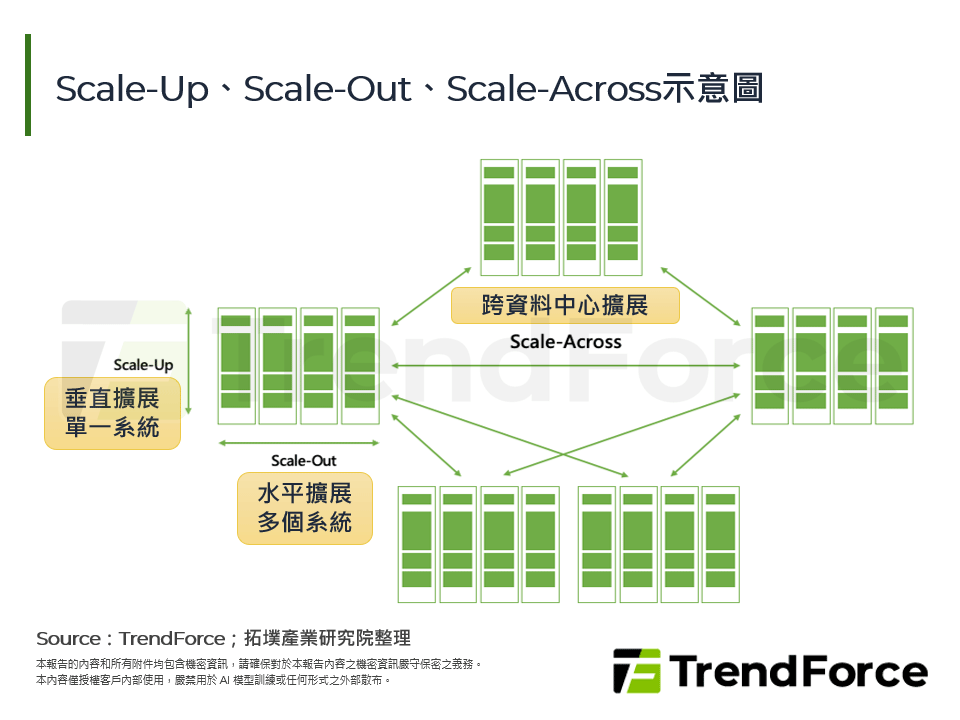
圖四 Scale-Up、Scale-Out、Scale-Across示意圖
圖五 傳統單端訊號示意圖
圖六 GRS運作示意圖
圖七 Clos Topology
圖八 Torus Topology
圖九 Full-Mesh Topology
圖十 Dragonfly Topology
圖十一 Dragonfly+Topology
圖十二 NVLink 1.0~4.0網路架構
圖十三 主要調變技術
圖十四 NVLink 5.0網路架構
圖十五 NVIDIA技術Roadmap
圖十六 VR300 NVL576
圖十七 NVLink Fusion示意圖
圖十八 RTX Pro Server
圖十九 Rubin CPX
圖二十 UALink 1.0架構
圖二十一 MI400 Helios rack
圖二十二 SUE架構
圖二十三 UB-Mesh互連架構
圖二十四 CloudMatrix384 Level 1互連架構
圖二十五 CloudMatrix384 Level 2互連架構
圖二十六 ALS架構
圖二十七 ETH-X架構
表一 Scale-Up、Scale-Out、Scale-Across比較
表二 主要網路拓樸類別
表三 主要網路拓樸的優缺點比較
表四 目前主要Scale-Up技術比較
表五 2014~2027年NVLink技術演進
表六 2024~2026年NVIDIA Rack Level網路硬體配置演進
表七 中國AI供應鏈
表八 中國主要AI加速器比較
表九 NVLink與中國Scale-Up技術比較
表十 各大廠商SuperPOD中Switch IC/XPU比例估計
表十一 2026年各大廠商Switch IC需求估計